
Document Image Understanding: Computational Image Processing in the Cultural Heritage Sector
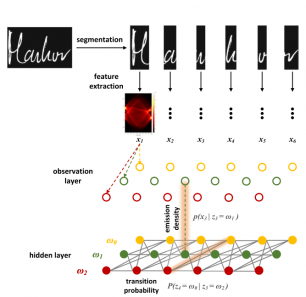
Textual documents, such as manuscripts and historical newspapers, make up an important part of our cultural heritage. Massive digitization projects have been conducted across the globe for a better preservation of, and for providing easier access to such, often vulnerable, documents. These digital counterparts also allow to unlock the rich information contained inside and across them thanks to various types of computational models for document image understanding. In this article, we will shed a light on the document image processing pipeline, from scan to information extraction. As it turns out, human perceptual-driven algorithms are among the most powerful approaches for generic document image understanding, required to deal with a myriad of layouts. In this context, we will in particular explain Gestalt visioning and the linked concept of text homogeneity that allows for enhanced layout analysis and even damage recognition, especially relevant in a cultural heritage setting. We conclude with a recent promising development, namely joint visual and language processing, that will take document image understanding to the next level in the future.

Related Articles

Use and Misuse of Machine Learning in Anthropology
Machine learning (ML), being now widely accessible to the research community at large, has fostered a proliferation of new and striking applications of these...

Special Issue on Information Processing in the Arts and Humanities
The papers in this special issue focus on information processing in the arts and humanities. Recent years have witnessed the emergence of various sophisticated information processing tools — including some involving artificial intelligence — that are capable of interrogating increasingly complex datasets in order to tackle challenges arising in a wide range of application domains.


Information Processing Challenges at the National Archives
The National Archives, U.K., faces a number of information processing challenges relating to the volume, variety and velocity of the data it handles, as well as its need to ensure value and veracity. This feature highlights some of these challenges as well as some of the work it is undertaking to address them.